
CockroachDB supports ACID transactions across arbitrary data in a distributed database. A discussion on how this works was first published on our blog three years ago. Since then, a lot has changed. Perhaps most notably, CockroachDB has transitioned from a key-value store to a full SQL database that can be plugged in as a scalable, highly-available replacement for PostgreSQL. It did so by introducing a SQL execution engine which maps SQL tables onto its distributed key-value architecture. However, over this period of time, the fundamentals of the distributed, atomic transaction protocol at the core of CockroachDB have remained untouched 1.
For the most part, this hasn’t been an issue. The transaction protocol in CockroachDB was built to scale out to tremendously large clusters with arbitrary data access patterns. It does so efficiently while permitting serializable multi-key reads and writes. These properties have been paramount in allowing CockroachDB to evolve from a key-value store to a SQL database. However, CockroachDB has had to pay a price for this consistency in terms of transaction latency. When compared to other consensus systems offering weaker transaction semantics, CockroachDB often needed to perform more synchronous consensus rounds to navigate a transaction. However, we realized that we could improve transaction latency by introducing concurrency between these rounds of consensus.
This post will focus on an extension to the CockroachDB transaction protocol called Transactional Pipelining, which was introduced in CockroachDB’s recent 2.1 release. The optimization promises to dramatically speed up distributed transactions, reducing their time complexity from O(n) to O(1), where n is the number of DML SQL statements executed in the transaction and the analysis is expressed with respect to the latency cost of distributed consensus.
The post will give a recap of core CockroachDB concepts before using them to derive a performance model for approximating transaction latency in CockroachDB. It will then dive into the extension itself, demonstrating its impact on the performance model and providing experimental results showing its effects on real workloads. The post will wrap up with a preview of how we intend to extend this optimization further in upcoming releases to continue speeding up transactions.
Distributed Transactions: A Recap
CockroachDB allows transactions to span an entire cluster, providing ACID guarantees across arbitrary numbers of machines, data centers, and geographical regions. This is all exposed through SQL — meaning that you can BEGIN a transaction, issue any number of read and write statements, and COMMIT the transaction, all without worrying about inconsistencies or loss of durability. In fact, CockroachDB provides the strongest level of isolation, SERIALIZABLE, so that the integrity of your data is always preserved.
There are a few competing ideas which combine to make this all possible, each of which is important to understand. Below is a brief introduction to each. For those interested in exploring further, more detail can be found in our architecture documentation.
Storage
At its most fundamental level, the goal of a durable database is to persist committed data such that it will survive permanently. This is traditionally performed by a storage engine, which writes bytes to a non-volatile storage medium. CockroachDB uses RocksDB, an embedded key-value database maintained by Facebook, as its storage engine. RocksDB builds upon its pedigree (LevelDB and more generally the Log-structured merge-tree (LSM tree) data structure) to strike a balance between high write throughput, low space amplification, and acceptable read performance. This makes it a good choice for CockroachDB, which runs a separate instance of RocksDB on each individual node in a cluster.
Even with software improvements like improved indexing structures and hardware improvements like the emergence of SSDs, persistence is still expensive both in terms of the latency it imposes on each individual write and in terms of the bounds it places on write throughput. For the remainder of this post, we’ll refer to the first cost here as “storage latency”.
Replication
Replicating data across nodes allows CockroachDB to provide high-availability in the face of the chaotic nature of distributed systems. By default, every piece of data in CockroachDB is replicated across three nodes in a cluster (though this is configurable)—we refer to these as “replicas”, and each node contains many replicas. Each individual node takes responsibility for persisting its own replica data. This ensures that even if nodes lose power or lose connectivity with one another, as long as a majority of the replicas are available, the data will stay available to read and write. Like other modern distributed systems, CockroachDB uses the Raft consensus protocol to manage coordination between replicas and to achieve fault-tolerant consensus, upon which this state replication is built. We’ve published about this topic before.
Of course, the benefits of replication come at the cost of coordination latency. Whenever a replica wants to make a change to a particular piece of its replicated data, it “proposes” that change to the other replicas and multiple nodes must come to an agreement about what to change and when to change it. To maintain strong consistency during this coordination, Raft (and other consensus protocols like it) require at least a majority of replicas (e.g. a quorum of 2 nodes for a replication group of 3 nodes) to agree on the details of the change.
In its steady-state, Raft allows the proposing replica to achieve this agreement with just a single network call to each other replica in its replication group. The proposing replica must then wait for a majority of replicas to respond positively to its proposal. This can be done in parallel for every member in the group, meaning that at a minimum, consensus incurs the cost of a single round-trip network call to the median slowest member of the replication group. For the remained of this post, we’ll refer to this as “replication latency”.
Distribution
Replicating data across nodes improves resilience, but it doesn’t allow data to scale indefinitely. For that, CockroachDB needs to distribute different data across the nodes in a cluster, storing only a subset of the total data on each individual node. To do this, CockroachDB breaks data into 64MB chunks, called Ranges. These Ranges operate independently and each manage its own N-way replication. The Ranges automatically split, merge, and move around a cluster to hold a suitable amount of data and to stay healthy (i.e. fully-replicated) if nodes crash or become unreachable.
A Range is made up of Replicas, which are members of the Range who hold a copy of its state and live on different nodes. Each Range has a single “leaseholder” Replica who both coordinates writes for the Range, as well as serves reads from its local RocksDB store. The leaseholder Replica is defined as the Replica at any given time who holds a time-based “range lease”. This lease can be moved between the Replicas as they see fit. For the purpose of this post, we’ll always assume that the leaseholder Replica is collocated with (in the same data center as) the node serving SQL traffic. This is not always the case, but automated processes like Follow-the-Workload do their best to enforce this collocation, and lease preferences make it possible to manually control leaseholder placement.
With a distribution policy built on top of consistent replication, a CockroachDB cluster is able to scale to an arbitrary number of Ranges and to move Replicas in these Ranges around to ensure resilience and localized access. However, as is becoming the trend in this post, this also comes at a cost. Because distribution forces data to be split across multiple replication groups (i.e. multiple Ranges), we lose the ability to trivially order operations if they happen in different replication groups. This loss of linearizable ordering across Ranges is what necessitates the distributed transaction protocol that the rest of this post will focus on.
Transactions
CockroachDB’s transactional protocol implements ACID transactions on top of the scalable, fault-tolerant foundation that its storage, replication, and distribution layers combine to provide. It does so while allowing transactions to span an arbitrary number of Ranges and as many participating nodes as necessary. The protocol was inspired in part by Google Percolator, and it follows a similar pattern of breaking distributed transactions into three distinct phases:
1. Preparation
A transaction begins when a SQL BEGIN statement is issued. At that time, the transaction determines the timestamp at which it will operate and prepares to execute SQL statements. From this point on, the transaction will perform all reads and writes at its pre-determined timestamp. Those with prior knowledge of CockroachDB may remember that its storage layer implements multi-version concurrency control, meaning that transactional reads are straightforward even if other transactions modify the same data at later timestamps.
When the transaction executes statements that mutate data (DML statements), it doesn’t write committed values immediately. Instead, it creates two things that help it manage its progress:
- The first write of the transaction creates a transaction record which includes the transaction’s current status. This transaction record acts as the transaction’s “switch”. It begins in the “pending” state and is eventually switched to “committed” to signify that the transaction has committed.
- The transaction creates write intents for each of the key-value data mutations it intends to make. The intents represent provisional, uncommitted state which lives on the same Ranges as their corresponding data records. As such, a transaction can end up spreading intents across Ranges and across an entire cluster as it performs writes during the preparation phase. Write intents point at their transaction’s record and indicate to readers that they must check the status of the transaction record before treating the intent’s value as the source of truth or before ignoring it entirely.
2. Commit
When a SQL transaction has finished issuing read and write statements, it executes a COMMIT statement. What happens next is simple - the transaction visits its transaction record, checks if it has been aborted, and if not, it flips its switch from “pending” to “committed”. The transaction is now committed and the client can be informed of the success.
3. Cleanup
After the transaction has been resolved and the client has been acknowledged, an asynchronous process is launched to replace all provisional write intents with committed values. This reduces the chance that future readers will observe the intents and need to check in with the intents' transaction record to determine its disposition. This can be important for performance because checking the status of another transaction by visiting its transaction record can be expensive. However, this cleanup process is strictly an optimization and not a matter of correctness.
That high-level overview of the transaction protocol in CockroachDB should be sufficient for the rest of this post, but those who are interested can learn more in our docs.
The Cost of Distributed Transactions in CockroachDB
With an understanding of the three phases of a distributed transaction in CockroachDB and an understanding of the abstractions upon which they are built, we can begin to construct a performance model that captures the cost of distributed transactions. Specifically, our model will approximate the latency that a given transaction will incur when run through CockroachDB 2.0 and earlier.
Model Assumptions
To begin, we’ll establish a few simplifying assumptions that will make our latency model easier to work with and visualize.
- The first assumption we’ll make is that the two dominant latency costs in distributed transactions are storage latency and replication latency. That is, the cost to replicate data between replicas in a Range and the cost to persist it to disk on each replica will dominate all other latencies in the transaction such that everything else can safely be ignored in our model. To safely make this approximation, we must assume that Range leaseholders are collocated with the CockroachDB nodes serving SQL traffic. This allows us to ignore any network latency between SQL gateways and Range leaseholders when performing KV reads and writes. As we discussed earlier, this is a safe and realistic assumption to make. Likewise, we must also assume that the network latency between the client application issuing SQL statements and the SQL gateway node executing them is sufficiently negligible. If all client applications talk to CockroachDB nodes within their local data centers/zones, this is also a safe assumption.
- The second assumption we’ll make is that the transactional workload being run is sufficiently uncontended such that any additional latency due to queuing for lock and latch acquisition is negligible. This holds true for most workloads, but will not always be the case in workloads that create large write hotspots, like YCSB in its zipfian distribution mode. It’s our belief that a crucial property of successful schema design is the avoidance of write hotspots, so we think this is a safe assumption to make.
- Finally, the third assumption we’ll make is that the CockroachDB cluster is operating under a steady-state that does not include chaos events. CockroachDB was built to survive catastrophic failures across a cluster, but failure events can still induce latencies on the order of a few seconds to live traffic as Ranges recover, Range leases change hands, and data is migrated in response to the unreachable nodes. These events are a statistical given in a large-scale distributed system, but they shouldn’t represent the cluster’s typical behavior –– so, for the sake of this performance model, it’s safe to assume they are absent.
The model will not be broken if any of these assumptions are incorrect, but it will need to be adapted to account for changes in latency characteristics.
Latency Model
First, let’s define exactly what we mean by “latency”. Because we’re most interested in the latency observed by applications, we define transactional latency as “the delay between when a client application first issues its BEGIN statement and when it gets an acknowledgement that its COMMIT statement succeeded.” Remember that SQL is “conversational”, meaning that clients typically issue a statement and wait for its response before issuing the next one.
We then take this definition and apply it to CockroachDB’s transaction protocol. The first thing we see is that because we defined latency from the client’s perspective, the asynchronous third phase of cleaning up write intents can be ignored. This reduces the protocol down to just two client-visible phases: everything before the COMMIT statement is issued by the client and everything after. Let’s call these two component latencies L_prep and L_commit, respectively. Together, they combine to a total transitional latency L_txn = L_prep + L_commit.
The goal of our model is then to characterize L_prep and L_commit in terms of the two dominant latency costs of the transaction so that we can define L_txn as a function of this cost. It just so happens that these two dominant latency costs are always paid as a pair, so we can define this unit latency as L_c, which can be read as “the latency of distributed consensus”. This latency is a function of both the replication layer and the storage layer. It can be expressed to a first-order approximation as the latency of a single round-trip network call to, plus a synchronous disk write on, the median slowest member of a replication group (i.e. Range). This value is highly dependent on a cluster’s network topology and on its storage hardware, but is typically on the order of single or double digit milliseconds.
To define L_prep in terms of the unit latency L_c, we first need to enumerate everything a transaction can do before a COMMIT is issued. For the sake of this model, we’ll say that a transaction can issue R read statements (e.g. SELECT * FROM t LIMIT 1) and W write statements (e.g. INSERT INTO t VALUES (1)). If we define the latency of a read statement as L_r and the latency of a write statement as L_w, then the total latency of L_prep = R * L_r + W * L_w. So far, so good. It turns out that because leaseholders in CockroachDB can serve KV reads locally without coordination (the committed value already achieved consensus), and because we assumed that the leaseholders were all collocated with the SQL gateways, L_r approaches 0 and the model simplifies to L_prep = W * L_w. Of course, this isn’t actually true; reads aren’t free. In some sense, this shows a limitation of our model, but given the constraints we’ve placed on it and the assumptions we’ve made, it’s reasonable to assume that sufficiently small, OLTP-like reads have a negligible cost on the latency of a transaction.
With L_prep reduced to L_prep = W * L_w, we now just need to characterize the cost of L_w in terms of L_c. This is where details about CockroachDB’s transaction protocol implementation come into play.
To begin, we know that the transaction protocol creates a transaction record during the first phase. We also know that the transaction protocol creates a write intent for every modified key-pair during this phase. Both the transaction record and the write intents are replicated and persisted in order to maintain consistency. This means that naively L_prep would incur a single L_c cost when creating the transaction record and an L_c cost for every key-value pair modified across all writing statements. However, this isn’t actually the cost of L_prep for two reasons:
- The transaction record is not created immediately after the transaction begins. Instead, it is collocated with and written in the same batch as the first write intent, meaning that the latency cost to create the transaction record is completely hidden and therefore can be ignored.
- Every provisional write intent for a SQL statement is created in parallel, meaning that regardless of how many key-value pairs a SQL statement modifies, it only incurs a single
L_ccost. A SQL statement may touch multiple key-value pairs if it touches a single row with a secondary index or if it touches multiple distinct rows. This explains why using multi-row DML statements can lead to such dramatic performance improvements.
Together this means that L_w, the latency cost of a single DML SQL statement, is equivalent to L_c. This is true even for the first writing statement which has the important role of creating the transaction record. With this substitution, we can then define L_prep = W * L_c
Defining L_commit in terms of the unit latency L_c is a lot more straightforward. When the COMMIT statement is issued, the switch on the transaction’s record is flipped with a single round of distributed consensus. This means that L_commit = L_c.
We can then combine these two components to complete our pre-2.1 latency model:
L_txn = (W + 1) * L_c
We can read this as saying that a transaction pays the cost of distributed consensus once for every DML statement it executes plus once to commit. For instance, if our cluster can perform consensus in 7ms and our transaction performs 3 UPDATE statements, a back-of-the-envelope calculation for how long it should take gives us 28ms.
The “1-Phase Transaction” Fast-Path
CockroachDB contains an important optimization in its transaction protocol that has existed since its inception called the “one-phase commit” fast-path. This optimization prevents a transaction that performs all writes on the same Range and commits immediately from needing a transaction record at all. This allows the transaction to complete with just a single round of consensus (L_txn = 1*L_c).
An important property of this optimization is that the transaction needs to commit immediately. This means that typically the fast-path is only accessible by implicit SQL transactions (i.e. single statements outside of a BEGIN; ... COMMIT; block). Because of this limitation, we’ll ignore this optimization for the remainder of this post and focus on explicit transactions.
Transactional Pipelining
The latency model we built reveals an interesting property of transactions in CockroachDB — their latency scales linearly with respect to the number of DML statements they contain. This behavior isn’t unreasonable, but its effects are clearly noticeable when measuring the performance of large transactions. Further, its effects are especially noticeable in geo-distributed clusters with very high replication latencies. This isn’t great for a database specializing in distributed operation.
What is Transactional Pipelining?
Transactional Pipelining is an extension to the CockroachDB transaction protocol which was introduced in v2.1 and aims to improve performance for distributed transactions. Its stated goal is to avoid the linear scaling of transaction latency with respect to DML statement count. At a high level, it achieves this by performing distributed consensus for intent writes across SQL statements concurrently. In doing so, it achieves its goal of reducing transaction latency to a constant multiple of consensus latency.
Prior Art (a.k.a. the curse of SQL)
Before taking a look at how transactional pipelining works, let’s quickly take a step back and explore how CockroachDB has attempted to address this problem in the past. CockroachDB first attempted to solve this issue in its v1.0 release through parallel statement execution.
Parallel statement execution worked as advertised - it allowed clients to specify that they wanted statements in their SQL transaction to run in parallel. A client would do so by suffixing DML statements with the RETURNING NOTHING specifier. Upon the receipt of a statement with this specifier, CockroachDB would begin executing the statement in the background and would immediately return a fake return value to the client. Returning to the client immediately allowed parallel statement execution to get around the constraints of SQL’s conversational API within session transactions and enabled multiple statements to run in parallel.
There were two major problems with this. First, clients had to change their SQL statements in order to take advantage of parallel statement execution. This seems minor, but it was a big issue for ORMs or other tools which abstract the SQL away from developers. Second, the fake return value was a lie. In the happy case where a parallel statement succeeded, the correct number of rows affected would be lost. In the unhappy case where a parallel statement failed, the error would be returned, but only later in the transaction. This was true whether the error was in the SQL domain, like a foreign key violation, or in the operational domain, like a failure to write to disk. Ultimately, parallel statement execution broke SQL semantics to allow statements to run in parallel.
We thought we could do better, which is why we started looking at the problem again from a new angle. We wanted to retain the benefits of parallel statement execution without breaking SQL semantics. This in turn would allow us to speed up all transactions, not just those that were written with parallel statement execution in mind.
Buffering Writes Until Commit
We understood from working with a number of other transaction systems that a valid alternative would be to buffer all write operations at the transaction coordinator node until the transaction was ready to commit. This would allow us to flush all write intents at once and pay the “preparation” cost of all writes, even across SQL statements, in parallel. This would also bring our distributed transaction protocol more closely in line with a traditional presumed abort 2-phase commit protocol.
The idea was sound and we ended up creating a prototype that did just this. However, in the end we decided against the approach. In addition to the complication of buffering large amounts of data on transaction coordinator nodes and having to impose conservative transaction size limits to accommodate doing so, we realized that the approach would have a negative effect on transaction contention in CockroachDB.
If you squint, write intents serve a similar role to row locks in a traditional SQL database. By “acquiring” these locks later into the lifecycle of a transaction and allowing reads from other transactions to create read-write conflicts in the interim period, we observed a large uptick in transaction aborts when running workloads like TPC-C. It turns out that performing all writes (i.e. acquiring all locks) at the end of a transaction works out with weaker isolation levels like snapshot isolation because such isolation levels allow a transaction’s read timestamp and its write timestamp to drift apart.
However, at a serializable isolation level, a transaction must read and write at the same timestamp to prevent anomalies like write skew from corrupting data. With this restriction, writing intents as early as possible serves an important role in CockroachDB of sequencing conflicting operations across transactions and avoiding the kinds of conflicts that result in transaction aborts. As such, doing so ends up being a large performance win even for workloads with just a small amount of contention.
Creating significantly more transaction aborts would have been a serious issue, so we began looking for other ways that we could speed up transactions without acquiring all locks at commit time. We’ll soon see that transactional pipelining allows us to achieve these same latency properties while still eagerly acquiring locks and discovering contention points within a transaction long before they would cause a transaction to abort.
A Key Insight
The breakthrough came when we realized that we could separate SQL errors from operational errors. We recognized that in order to satisfy the contract for SQL writes, we only need to synchronously perform SQL-domain constraint validation to determine whether a write should return an error, and if not, determine what the effect of the write should be (i.e. rows affected). Notably, we realized that we could begin writing intents immediately but don’t actually need to wait for them to finish before returning a result to the client. Instead, we just need to make sure that the write succeeds sometime before the transaction is allowed to commit.
The interesting part about this is that a Range’s leaseholder has all the information necessary to perform constraint validation and determine the effect of a SQL write, and it can do this all without any coordination with other Replicas. The only time that it needs to coordinate with its peers is when replicating changes, and this doesn’t need to happen before we return to a client who issued a DML statement. Effectively, this means that we can push the entire consensus step out of the synchronous stage of statement execution. We can turn a write into a read and do all the hard work later. In doing so, we can perform the time-consuming operation of distributed consensus concurrently across all statements in a transaction!
Asynchronous Consensus
In order to make this all fit together, we had to make a few changes to CockroachDB’s key-value API and client. The KV API was extended with the concept of “asynchronous consensus”. Traditionally, a KV operation like a Put would acquire latches on the corresponding Range’s leaseholder, determine the Puts effect by evaluating against the local state of the leaseholder (i.e. creating a new write intent), replicate this effect by proposing it through consensus, and wait until consensus succeeds before finally returning to the client.
Asynchronous consensus instructs KV operations to skip this last step and return immediately after proposing the change to Raft. Using this option, CockroachDB’s SQL layer can avoid waiting for consensus during each DML statement within a transaction––this means we no longer need to wait W *L_c during a transaction’s preparation phase.
Proving Intent Writes
The other half of the puzzle is that transactions now need to wait for all in-flight consensus writes to complete before committing a transaction. We call this job of waiting for an in-flight consensus write “proving” the intent. To prove an intent, the transaction client, which lives on the the SQL gateway node performing a SQL transaction, talks to the leaseholder of the Range which the intent lives on and checks whether it has been successfully replicated and persisted. If the in-flight consensus operation succeeded, the intent is successfully proven. If it failed, the intent is not proven and the transaction returns an error. If consensus operation is still in-flight, the client waits until it finishes.
To use this new mechanism, the transaction client was modified to track all unproven intents. It was then given the critical job of proving all intent writes before allowing a transaction to commit. The effect of this is that provisional writes in a transaction never wait for distributed consensus anymore. Instead, a transaction waits for all of its intents to be replicated through consensus in parallel, immediately before it commits. Once all intent writes succeed, the transaction can flip the switch on its transaction record from PENDING to COMMITTED.
Read-Your-Writes
There is an interesting edge case here. When a transaction writes a value, it should be able to read that same value later on as if it had already been committed. This property is sometimes called “read-your-writes”. CockroachDB’s transaction protocol has traditionally made this property trivial to enforce. Before asynchronous consensus, each DML statement in a transaction would synchronously result in intents that would necessarily be visible to all later statements in the transaction. Later statements would notice these intents when they went to perform operations on the same rows and would simply treat them as the source of truth since they were part of the same transaction.
With asynchronous consensus, this guarantee isn’t quite as strong. Now that we’re responding to SQL statements before they have been replicated or persisted, it is possible for a later statement in a transaction to try to access the same data that an earlier statement modified, before the earlier statement’s consensus has resulted in an intent.
To prevent this from causing the client to miss its writes, we create a pipeline dependency between statements in a transaction that touch the same rows. Effectively, this means that the second statement will wait for the first to complete before running itself. In doing so, the second intent write first proves the success of the first intent write before starting asynchronous consensus itself. This results in what is known as a “pipeline stall”, because the pipeline within the transaction must slow down to prevent reordering and ensure that dependent statements see their predecessor’s results.
It is worth noting that the degenerate case where all statements depend on one-other and each results in a pipeline stall is exactly the case we had before - all statements are serialized with no intermediate concurrency.
This mix of asynchronous consensus, proving intent writes, and the strong ordering enforced between dependent statements that touch the same rows combine to create transactional pipelining.
Latency Model: Revisited
Transactional pipelining dramatically changes our latency model. It affects both the preparation phase and the commit phase of a transaction and forces us to rederive L_prep and L_commit. To do so, we need to remember two things. First, with transactional pipelining, intent writes no longer synchronously pay the cost of distributed consensus. Second, before committing, a transaction must prove all of its intents before changing the status on its transaction record.
We hinted at the effect of this change on L_prep earlier - writing statements are now just as cheap as reading statements. This means that L_prep approaches 0 and the model simplifies to L_txn = L_commit.
However, L_commit is now more expensive because it has to do two things: prove all intents and write to its transaction record, and it must do these operations in order. The cost of the first step is of particular interest. The transaction client is able to prove all intents in parallel. The effect of this is that the latency cost of proving intent writes at the end of a transaction is simply the latency cost of the slowest intent write, or L_c. The latency cost of the second step, writing to the transaction’s record to flip its switch does not change.
By adding these together we arrive at our new transaction latency model:
L_txn = L_commit = 2 * L_c
We can read this as saying that a transaction whose writes cross multiple Ranges pays the cost of distributed consensus twice, regardless of the reads or the writes it performs. For instance, if our cluster can perform consensus in 7ms and our transaction performs 3 UPDATE statements, a back-of-the-envelope calculation for how long it should take gives us 14ms. If we add a fourth UPDATE statement to the transaction, we don’t expect it to pay an additional consensus round trip - the estimated cost is constant regardless of what else the transaction does.
Benchmark Results
Simplified performance models are great for understanding, but they are only as useful as they are accurate. Before releasing v2.1, we ran a number of experiments with and without transactional pipelining enabled to see what its performance impact is in practice.
Inter-Node Latency vs. Txn Latency
The first experiment we ran was looking at TPC-C’s New-Order transaction. TPC-C is an industry standard benchmark that we have spent significant time looking at in the past. The backbone of the benchmark is its New-Order business transaction, which is a mid-weight, read-write transaction with a high frequency of execution and stringent response times.
With a careful attention to multi-row statements, the transaction can be composed of as few as 4 read-only statements and 5 read-write statements. Given this detail, we can use the latency models we derived early to estimate how long we expect the transaction to take with and without transactional pipelining. With transactional pipelining, we expect the transaction to take two times the distributed consensus latency. Without it, we expect the transaction to take six times the distributed consensus latency.
We put these models to the test on a three-node cluster within the same GCE zone. We then used the tc linux utility to manually adjust inter-node round trip latency. The client-perceived latency of a New-Order transaction was measured as the synthetic latency grew from 0ms up to 90ms. The experiment was run twice, first with the kv.transaction.write_pipelining_enabled cluster setting set to true and next with it set to false.
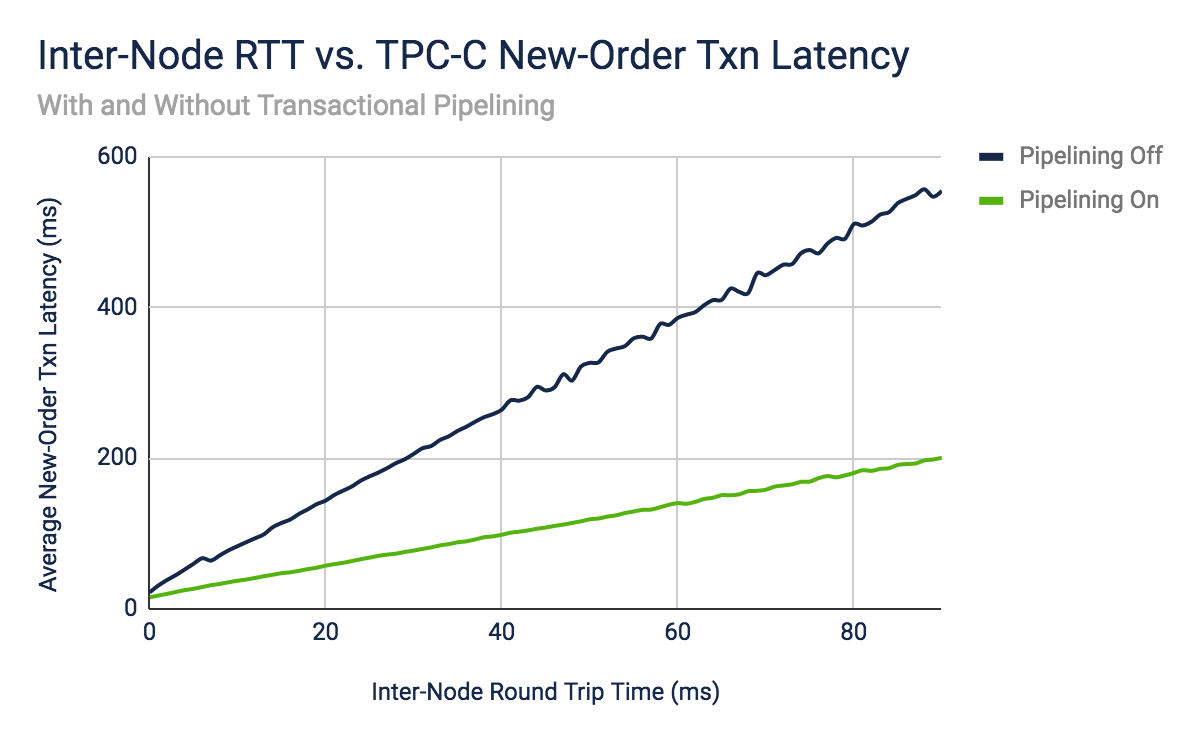
The graph demonstrates that our latency model was spot on. The line without transactional pipelining enabled has a slope of 6, demonstrating that every extra millisecond of inter-node latency results in six extra milliseconds of transactional latency. Meanwhile, the line with transactional pipelining enabled has a slope of 2, demonstrating that every extra millisecond of inter-node latency results in two extra milliseconds of transactional latency. This indicates that without transactional pipelining, transactional latency is dependent on the number of DML statements in the txn, which in this case is 5. With transactional pipelining, transactional latency is not dependent on the number of DML statements in the txn.
DML Statement Count vs. Txn Latency
To dig into this further, we performed a second experiment. This time, we fixed the inter-node round trip latency at 10ms and instead adjusted the number of DML statements performed within a transaction. We started with a single DML statement per transaction and increased that up through 256. Finally, we plotted the client-perceived transactional latency with and without transactional pipelining enabled.
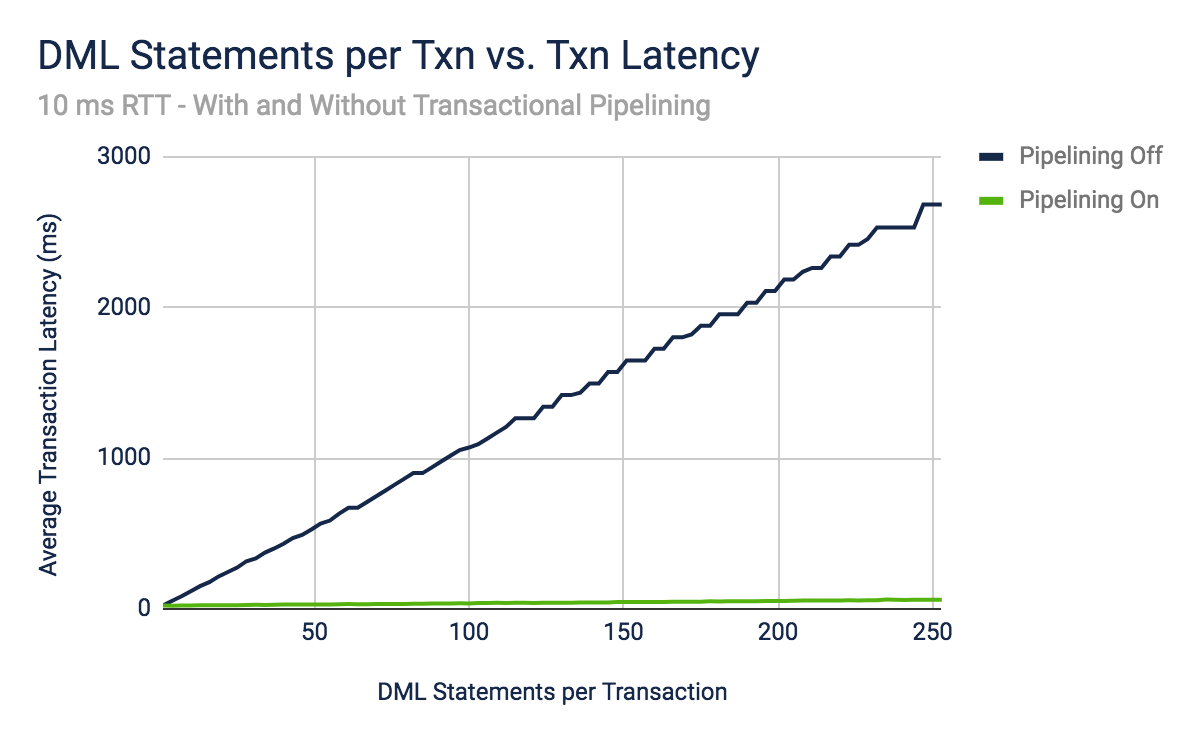
The trial with transactional pipelining performs so much better than trial without that it’s hard to see what’s going on. Let’s use a logarithmic scale for the y-axis so we can dig in perform a real comparison.
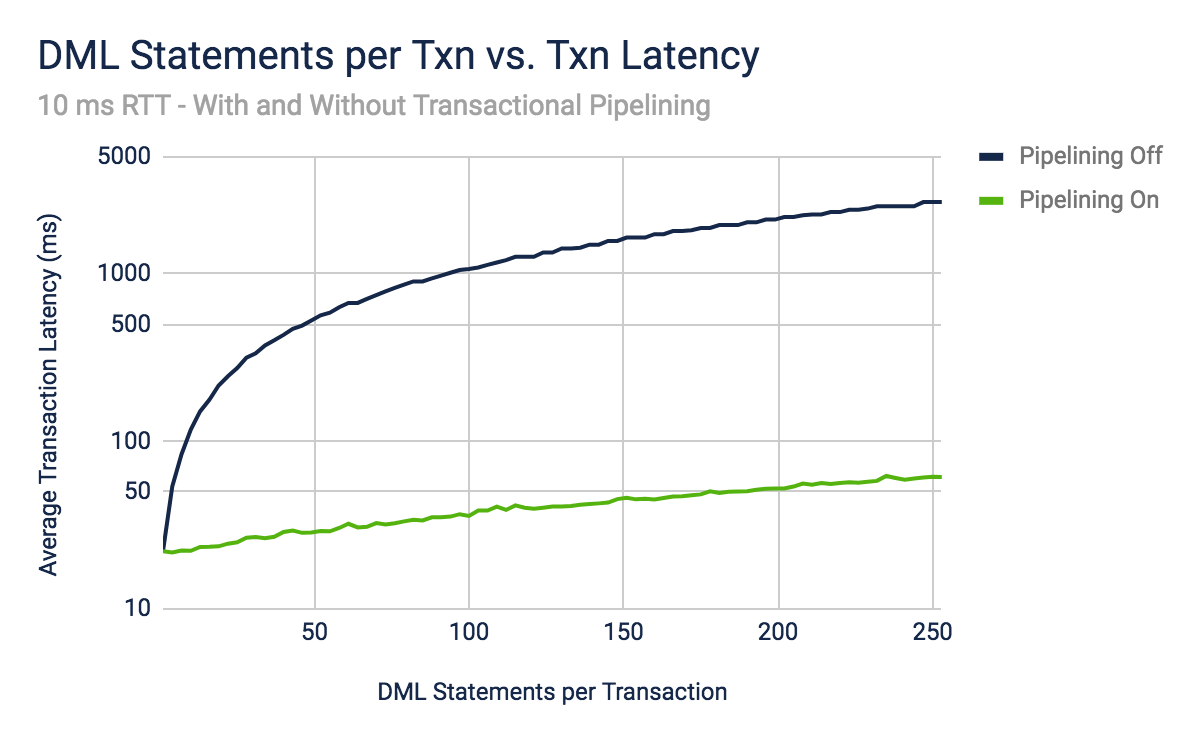
With a logarithmic y-axis, the graph reveals a few interesting points. To begin, it shows that when a transaction only performs a single DML statement, pipelining makes no difference and the transaction latency is twice the consensus latency. This lines up with our intuition and our performance model. More critically, it demonstrates the difference in how transaction latency scales with respect to DML statement count with and without transactional pipelining. With transactional pipelining disabled, transaction latency scales linearly with respect to the DML statement count. With transactional pipelining enabled, transaction latency scales sub-linearly with respect to the DML statement count. This is a clear demonstration of the effectiveness of transactional pipelining and shows what a major improvement it can provide. It is also in line with what our latency models would predict.
However, even in the second line, the scaling is not completely constant. In some senses, this reveals a failing of our new latency model, which assumes that the synchronous stage of each DML statement is free with transactional pipelining. Of course, in reality, each additional DML statement still does have some latency cost. For instance, in this setup, each additional DML statement looks to cost a little under half a millisecond. This cost is negligible compared to the dominant cost of distributed consensus with single and double digit DML statement counts, but starts to make a difference towards the upper end of the graph. This demonstrates both the utility of performance models and the importance of putting them to the test against real-world experimentation. These experiments help us to see when secondary costs can be discounted and under which conditions they start to matter.
Other Benchmarks
These two tests demonstrate how effectively transactional pipelining achieves its goals. Those interested can explore even more tests that we ran during the development of transactional pipelining in the associated Github pull request The testing revealed other interesting behavior, like that even when replication latencies were negligible, transactional pipelining improved latency and throughput of benchmarks because it permits increased levels of concurrency through the storage layer.
We’ve found these tests to be extremely valuable in justifying the creation of transactional pipelining, but it would have been impossible to test everything. We’d love to hear from others about their experience with the optimization and whether it provides a speedup in their unique workloads. We encourage anyone interested to open a Github issue to discuss their results. This will help us continue to optimize CockroachDB going forward.
What’s Next?
Transactional pipelining is part of CockroachDB v2.1. Use of the feature is controlled by the kv.transaction.write_pipelining_enabled cluster setting. This setting defaults to true, which means that when you upgrade to version 2.1, you’ll immediately begin taking advantage of the optimization. You can expect a speedup in your transactions across the board.
However, we’re not done trying to reduce transactional latency. The latency model we left off with scales independently with respect to the number of DML statements in the transaction, but it still incurs the latency cost of two rounds of distributed consensus. We think it’s possible to cut this in half. In fact, we have a concrete proposal for how to do it called “parallel commits”. The optimization deserves a separate blog post of its own, but we can summarize it here as follows: Parallel commits allows the two operations that occur when a transaction commits, proving provisional intent writes and flipping the switch on the transaction record, to run in parallel. Or in more abstract terms — it parallelizes the prepare and the commit phases of the 2-phase commit protocol. Effectively, this reduces the cost of L_commit in our new latency model to just a single L_c.
The optimization is still in development, and we’re actively exploring how best to introduce it into future releases of CockroachDB. If distributed transactions are your jam, check out our open positions here.
Footnote
-
One exception to this is that CockroachDB’s concurrency protocol has moved from optimistic to pessimistic. This deserves an entire blog post of its own, but what it means in practice is that contending transactions rarely restart each other anymore. Instead, contending transactions queue up to make modifications, meaning that transaction intents act a lot more like traditional locks. This approach is more complicated because it requires a distributed deadlock detection algorithm, but we justified making the switch after seeing how much better it performed for highly-contended workloads. More detail about this can be found in our docs. ↩︎


