
Maintaining high availability when an application is spread out all over the world is a hard problem to solve. Starburst, a modern solution that addresses data silos and speed of access problems for their customers, handles exabytes of scale across a five-region deployment, while keeping read-latencies low everywhere.
In this blog we’ll explore why Starburst made the multi-region investment, how they architected it to hit latency/survivability goals, and why CockroachDB is the right fit for global metadata replication. You can also watch this video of Starburst’s CTO, David Phillips, explaining their architecture and how they deploy CockroachDB (there are more CockroachDB customer presentations here.):
What is Starburst?
Starbust has its origins in Trino (formerly known as Presto), the open source query engine that allows users to query data across distributed data sources and aggregate the results. Trino generates all sorts of data such as user accounts/permissions, user metadata, query plan diagnostics data, and query usage logs.
Customers from all over the world use Starburst to get more value out of their distributed data because the data in Starburst is fast and easy to access, no matter where it lives. To make this possible, they deliver a SQL-based MPP query engine for data lake, data warehouse, or data mesh.
Because of their global customer base Starburst decided to take on the challenge of building an application that could span across multiple geographies, achieve massive scale, and ensure 24/7 uptime. This is why they built Starburst Galaxy on CockroachDB.
How to handle distributed data
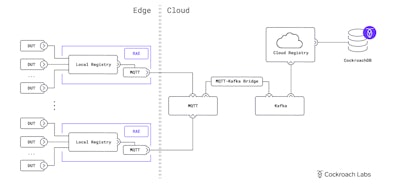
It’s important to understand that Starburst’s architecture is massively decentralized because their customers are from all over the world and their customers’ data is distributed. This kind of wide-scale global distribution creates a unique challenge: how do you build a centralized product with a distributed architecture?
Since Starburst runs Trino in multiple clouds and in multiple regions, they need their customers to be able to access their data in multiple clouds and regions. This requires elegant answers to two questions:
- How do you efficiently manage and scale multi-region, multi-cloud architecture ?
- How do you move data close to customers for latency? (Speed of access and time-to-insight are pivotal differentiators for Starburst so they need to nail these.)
They also needed: a primary application database for the Starburst Galaxy web application which stores standard data like account information such as protected passwords. They also built their own metastore service and needed a reliable backend for their home baked metastore so customers could access and query data anywhere globally. Replicating this metadata globally would be necessary, yet difficult to achieve without the right infrastructure to support them.
Given all these requirements, Starbursts’ options were limited. They didn’t want to use Spanner because they didn’t want to be tied to a cloud provider. They could have used Postgres, but they would have had to replicate it themselves and figure out the supporting tech for multi-region deployments.
And they didn’t want to write it from scratch. They needed a cloud-agnostic solution that solved the multi-region challenge for them, which led them to CockroachDB.
“Why would I have my engineering team try to solve the multi-region problem when there’s an engineering team out there that’s already built a solid solution? We needed to make defensive, smart technology solution choices because we are on the hook for our customer’s data.” - Ken Pickering, VP of Engineering
How to keep read latency low across regions
With customers in the United States, Europe, Asia Pacific, and South America, the danger of a slow platform was a primary concern. To solve for that danger they use mostly read-heavy tables (a luxury of choice that not every application has). Ideally, when a customer queries their data, they hit their local read node and do not traverse the world to access the data. This means that their reads need to be near-instant, while writes can be somewhat slower.
Given the nature of this data, they decided to leverage CockroachDB’s global table locality to ensure that read latency is really low. They were willing to compromise write latency in this scenario (excellent read here on Global tables if you’re curious).
How to set up regions to survive region failures
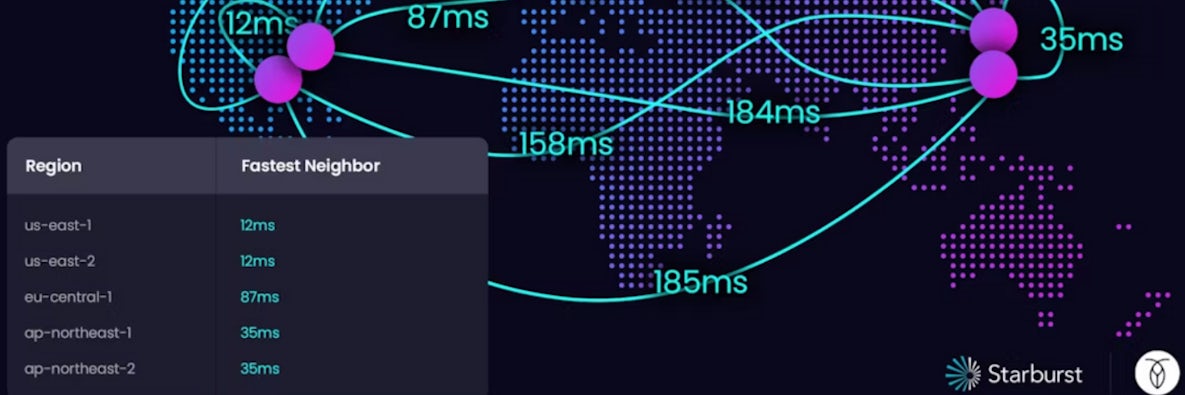
Prior to going into production, Sturburst worked with the Cockroach Labs team to determine the best scenario for minimizing latency. For example, they could have deployed their application across 4 AWS regions spread out among us-west-1, us-east1, eu-central, and ap-northeast-1.
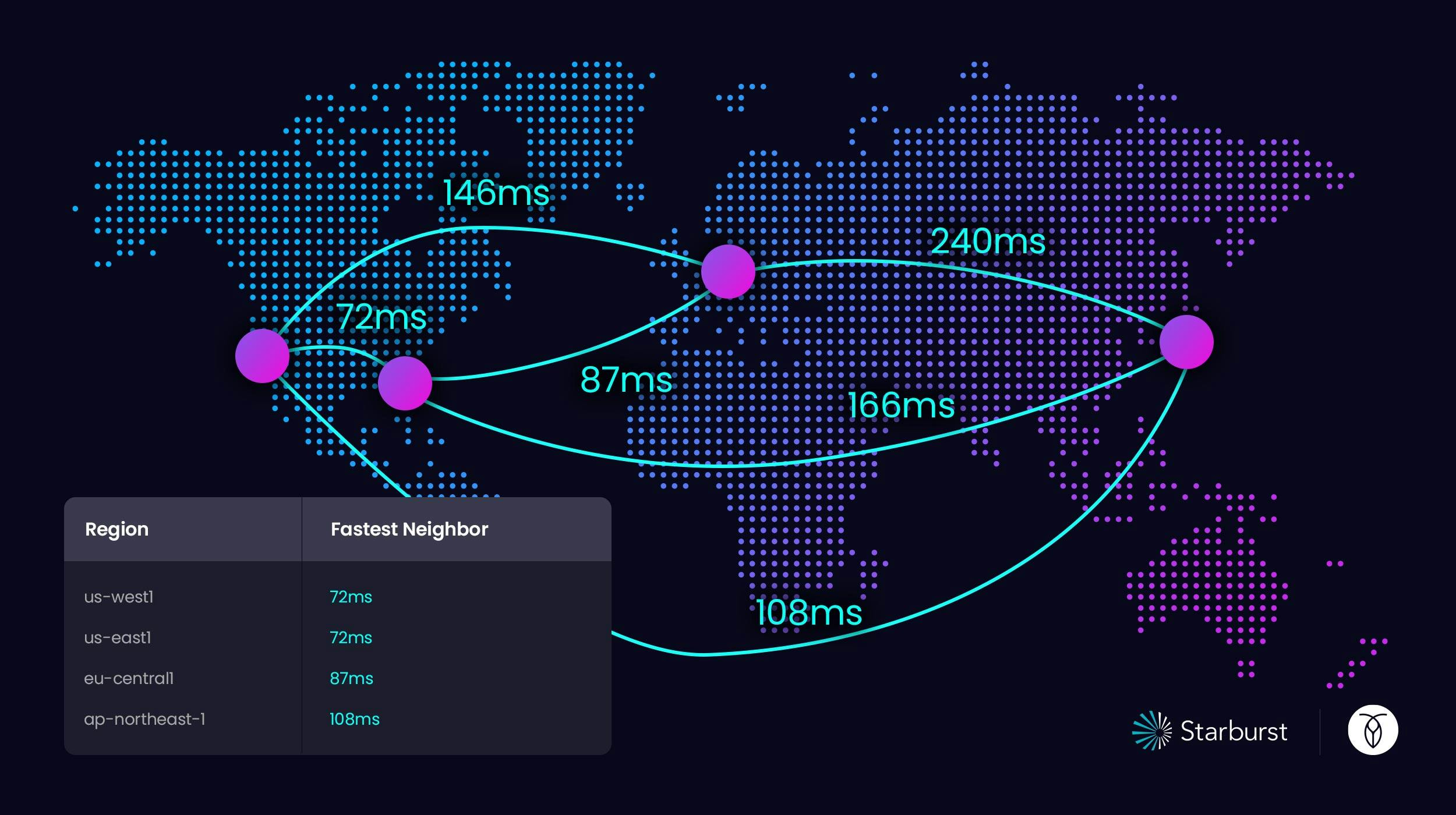
However, their survival goal = region failure, meaning that if an entire region went down (and assuming the app in that region is also down) their customers would be able to access their data from a replica in a region nearby. Given this survival goal, it was best to rearrange their setup and add an additional region.
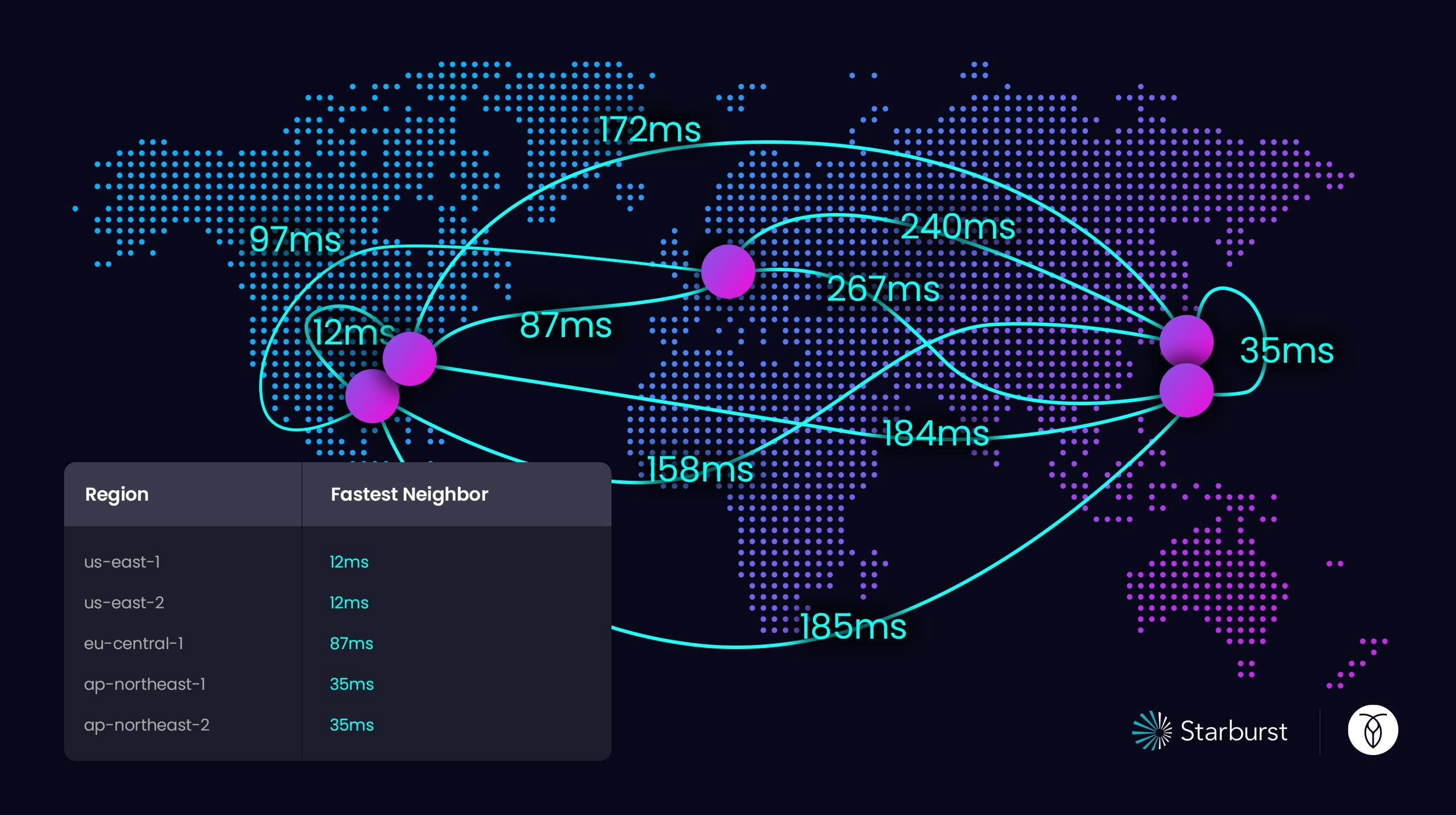
In the event that a region goes down, they have a plan:
- US users can have replicas in us-east-1, us-east-2 and eu-central-1
- APAC users can have replicas in ap-northeast-1, ap-northeast-2 and us-east-2
- EU users can have replicas in eu-central-1, us-east-1, and us-east-2)
Since Starburst went into production in November 2021, their approach to achieve their survival goals and minimize latency for their customers has been successful.
“We have to assume that at some point, some of the regions will go down. We can’t have central gravity for this storage – it’s not possible. So even if our primary control plane goes down and a failover hasn’t happened, the customers can still get access to their data.” - Ken Pickering, VP of Engineering
To learn more about how Starbursts’ use case directly from CTO David Philips, check out this talk: How Starburst uses CockroachDB to power Starburst Galaxy.