With the rapid adoption of Kubernetes in organizations and the push to standardize the orchestration of resources with this approach, databases are now also being deployed into Kubernetes.
Historically, persistent workloads like databases were not recommended to be deployed into Kubernetes because it was complex to manage how data would be stored. This was a result of Kubernetes originally being designed for non-persistent microservice architectures. However, in more recent times new database vendors are emerging with software built from the ground up to run in this environment.
Kubernetes mandates how the networking is deployed and configured in a single cluster to allow communication between pods. But this single-cluster architecture doesn’t lend itself well to multi-region database deployments, where customers want to implement some use cases like cross regional data access, regional data protection regulations, or reducing application latency. For multi-region databases or databases with multiple instances running in different regions, all database instances are deployed into individual Kubernetes clusters running in each of the required regions. In such a scenario, it is challenging to enforce inter-cluster communication at pod-level, security policy enforcement at pod-level, and connect to services running in pods in different regions.
The complex Kubernetes multi-cluster network architecture stunts business growth as it costs more to scale, needs more resources to implement, and requires iterations to accommodate more regions, which is time-consuming and not scalable.
CockroachDB is an example of a multi-region database that requires secure, multi-cluster communication across different regions. CockroachDB is a distributed SQL database designed to handle large-scale, global applications. It’s particularly well-suited for multi-regional data use cases for several reasons:
Distributed architecture
CockroachDB uses a distributed architecture that allows it to span multiple regions and provide low-latency access to data regardless of where it’s stored. This means that users in one region can access data stored in another region without experiencing significant delays.
Strong consistency
CockroachDB provides strong consistency guarantees, which means that data is always consistent and up-to-date across all regions. This is important for multi-region use cases where data is frequently updated, as it ensures that all users are working with the same data.
Automatic data replication
CockroachDB automatically replicates data across regions to ensure high availability and fault tolerance. This means that if one region goes down, data is still accessible from other regions.
Multi-active availability
CockroachDB allows for multi-active availability, which means that multiple regions can be actively serving requests at the same time. This can improve application performance by distributing load across multiple regions.
Cloud native
CockroachDB is cloud native and can be easily deployed on popular cloud platforms like AWS, GCP, and Azure. It also supports hybrid and on-premises deployments, making it flexible for a variety of use cases.
Using Calico, and specifically, the Calico clustermesh, CockroachDB helps its customers enable inter-cluster pod communication, achieve scalability, and implement granular security controls to solve the challenges of a multi-cluster network architecture. This step-by-step guide will show you how you can achieve the same outcome in just six steps.
*Note: To enable Calico’s federated endpoints identity at step five, you will need to follow the instructions outlined and upgrade from Calico Open Source to Calico Cloud.
What is the Calico clustermesh?
Calico’s clustermesh addresses the multi-cluster network architecture requirements for CockroachDB. Calico’s network and security design relies on BGP to configure the routes between Kubernetes workloads, allowing customers to quickly scale horizontally across different regions and apply security policies cross-cluster.
Enabling inter-cluster pod communication is just the first part of solving the multi-region database challenge. Once you do so, you have already knocked down a wall and replaced it with a door. This door needs access control and security to ensure you are not increasing the attack surface in your environment.
With upgrading to Calico Cloud and enabling Calico’s federated endpoints identity, you can define granular security controls between multiple clusters by creating policies in one cluster that reference pods in another cluster.
Step 1: Set up multi-region AWS network configuration and virtual machines
We have created an implementation guide on GitHub that includes step-by-step commands to build the environment and test the solution.
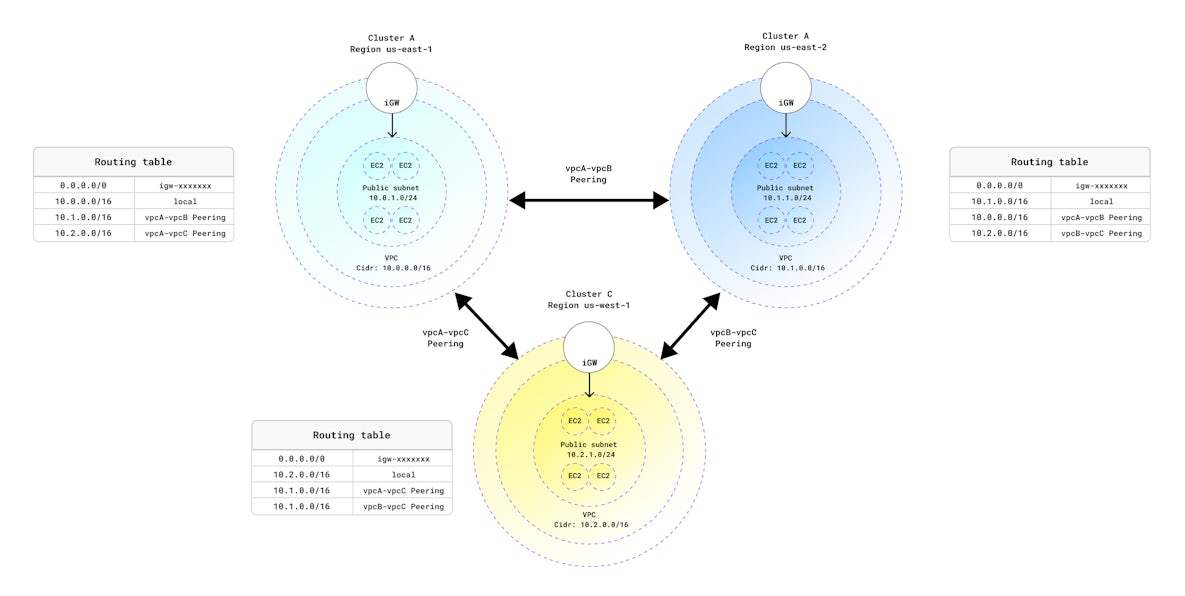
First, we need to build an infrastructure to work with. In our example, we will use AWS, but you can achieve the same setup on any cloud provider or even on-premises. Review the following diagram to get an idea of the resource we will deploy.

As a part of this example using AWS, the following resources will be created:
- 3 virtual private clouds (VPCs) in 3 different regions: In our example, I used us-east-1, us-east-2, and us-west-1 regions, but feel free to pick any regions you want.
- A public subnet in each VPC: A subnet associated with a route table, with a route to an Internet gateway.
- Internet gateway attached to each VPC: An Internet gateway provides a target in your VPC route tables for Internet-routable traffic.
- Route table and route for the 3 different VPCs: The first route points all traffic (0.0.0.0/0) to the Internet gateway, then two more routes point to the VPC peering connections.
- VPC peering connection: VPC peering allows nodes to talk to each other.
- 4 instances into each region: I used m5.large instances and Ubuntu 18.04 Image in this example.
The most important thing in this stage is to avoid any IP address overlap. Here is the IP address schema we used:
| Region | VPC CIDR | Subnet |
|---|---|---|
| us-east-1 | 10.0.0.0/16 | 10.0.1.0/24 |
| us-east-2 | 10.1.0.0/16 | 10.1.1.0/24 |
| us-west-1 | 10.2.0.0/16 | 10.2.1.0/24 |
At this stage, you have 4 instances in each region and you should be able to ping these instances across the regions.
Step 2: Provisioning Kubernetes cluster in each region
In this section, we will install kubeadm cluster in each region with the Calico CNI. You can use any Kubernetes distribution of your choice.
Again, avoid overlapping pod and service IP addresses across the clusters. Here are the IP CIDRs I used for this deployment.
Pod IP setup:
- Cluster A: 192.168.0.0/18
- Cluster B: 192.168.64.0/18
- Cluster C: 192.168.128.0/18
Service IP setup:
- Cluster A: 172.20.0.0/16
- Cluster B: 172.21.0.0/16
- Cluster C: 172.22.0.0/16
In module 2 of this implementation guide, you will find a script to install kubeadm and the Calico CNI on each region preconfigured with the above IP scheme.
Step 3: Enable inter-cluster pod communication
The aim of this module is to enable pod-to-pod communication between the 3 clusters. To achieve this, we will use a route reflector in each cluster to establish peering and route exchanges between clusters using eBGP (BGP between different AS). The eBGP peering will export all routes learned from iBGP (in-clustermesh), so we need to configure each Calico cluster using its AS.
Follow these steps in module 3 of the implementation guide to complete these configurations. The following diagram illustrates the final BGP configuration:

At this point, you have enabled inter-cluster pod communication between the three regions. Now, it’s time to deploy CockroachDB.
Step 4: Deploy CockroachDB across multiple regions
CockroachDB is a cloud-native, geo-distributed SQL database, made to provide elastic scalability with built-in survivability. It distributes data globally, regardless of where the user is located, ensuring optimal user experience. You can achieve this across any combination of cloud providers remaining completely cloud agnostic.
Follow the steps in module 4 of the implementation guide, which will walk you through the steps required to implement CockroachDB across three Kubernetes clusters. Now that we have cross-cluster networking provided by Calico, we need to update CoreDNS running in each cluster to allow the CockroachDB pod to resolve the names of other CockroachDB pods running in remote clusters.
Below is an example of the changes made. Detailed instructions can be found in the implementation guide.
us-east-2.svc.cluster.local:53 { # <---- Modify
log
errors
ready
cache 10
forward . 172.21.0.10 { # <---- Modify
}
}
us-west-1.svc.cluster.local:53 { # <---- Modify
log
errors
ready
cache 10
forward . 172.22.0.10 { # <---- Modify
}
}
All communications between CockroachDB nodes and clients are encrypted using TLS, ensuring the security of the data within the cluster. As a result, a number of certificates have to be created during the installation process. This is a straightforward process as the Cockroach binary has a CA built-in for this purpose. Once these certificates are created, they are stored in Kubernetes secrets in each of the clusters.

Once all the certificates have been stored correctly, we are ready for the next step, where CockroachDB is deployed as a Kubernetes StatefulSet in each cluster. Each pod of the StatefulSet requires some persistent storage via PersistentVolumeClaim (PVC). Please ensure you have a default StorageClass available prior to deploying the other required resources.
CockroachDB provides examples of Kubernetes manifests in their GitHub repo here. These manifests include all of the resources required to deploy CockroachDB successfully. In module 4 of the implementation guide, these have been updated to work with this demo. Deploy these by using kubectl.
The final step is to initialize the database using the following command:
kubectl exec \
--namespace us-east-1 \
-it cockroachdb-0 \
-- /cockroach/cockroach init \
--certs-dir=/cockroach/cockroach-certs
You now have a multi-regional CockroachDB cluster.
Step 5: Securing CockroachDB deployment across clusters in multiple regions
To use Calico federated endpoints identity and services, you will need Calico Cloud. Calico Cloud provides all the security features that you need to secure your workloads across clusters. Calico’s federated endpoints identity provides the ability to define granular security controls between multiple clusters by creating policies in one cluster that reference pods in another cluster. Follow the steps in module 5 to upgrade from Calico Open Source to Calico Cloud.
Final step: Enable endpoint identity federation to create cross-cluster security policies
This module aims to configure each cluster to pull endpoint data from remote clusters. Federating endpoints allows teams to write policies in a local cluster that references/selects endpoints in remote clusters, improving efficiency and optimizing the self-service experience.
Follow the steps in module 6 to enable the endpoint identity federation. Afterward, you should be able to write network policies that reference endpoints in the remote clusters
Example policy: Label each workload based on their location or region name (e.g.,. geography=us-east-1), then create a global security policy to allow only ports 26257 and 8080, which are required to allow cockroachDB to communicate. Then block everything else. Here is how should the policy look like:
apiVersion: projectcalico.org/v3
kind: GlobalNetworkPolicy
metadata:
name: default.geography-isolation
spec:
tier: default
selector: geography == "us-east-1"
ingress:
- action: Allow
protocol: TCP
source:
selector: (geography == "us-east-2" && geography == "us-west-1")
destination:
ports:
- '26257'
- '8080'
- action: Deny
source:
selector: (geography == "us-east-2" && geography == "us-west-1")
destination: {}
egress:
- action: Allow
protocol: TCP
source: {}
destination:
selector: (geography == "us-east-2" && geography == "us-west-1")
ports:
- '26257'
- '8080'
- action: Deny
source: {}
destination:
selector: (geography == "us-east-2" && geography == "us-west-1")
doNotTrack: false
applyOnForward: false
preDNAT: false
types:
- Ingress
- Egress
Conclusion
The Calico clustermesh will help you to scale quickly and securely across Kubernetes clusters and different geographical locations with little complexity. It’s a one-stop shop where you can enable pod-to-pod communication, secure traffic with federated security policies, and get across-region observability from a centralized UI. This is imperative when running mission-critical applications across multiple regions, clouds or even hybrid deployments. Along with running CockroachDB as the database allows consistent data to be accessed where needed globally quickly and securely, a challenge previously impossible to solve.
To learn more about new cloud-native approaches for establishing security and observability for containers and Kubernetes, check out this O’Reilly eBook, authored by Tigera.