
 [ Guides ]
[ Guides ]
Best practices for multi-cloud
Save time and money by approaching multi-cloud the right way.
Get your copy of the reportDo you remember December 7, 2021?
If you work in ops, you might – that’s one of the recent examples of a major public cloud region encountering serious issues, and breaking a large number of popular applications, from Disney+ to Ticketmaster, in the process.
The outage was resolved, as they always are. But this, and other incidents like it, lay bare that even though the major public clouds can all offer solid uptime, relying on just one of them can still be costly.
Even a short outage once every few years can cost millions when you’re operating at scale. According to a 2022 study from analyst firm Enterprise Management Associates (EMA) and AIOps company BigPanda, the average cost of downtime is $12,900 per minute. For large enterprises, the costs are even higher – often millions of dollars per hour, and that’s before you factor in all of the indirect costs such as reputational damage.
That’s just one of the reasons why most companies are moving to or considering multi-cloud deployments.
What is a multi-cloud database?
A multi-cloud database is exactly what it sounds like: a database that is implemented across one or more cloud systems.
A multi-cloud database is distributed by nature – it runs on the hardware of at least two different cloud platforms. Despite this, a truly multi-cloud database can operate a single cluster (or multiple clusters) that span multiple clouds. True multi-cloud databases allow your application to treat the database much like a single-instance database operating on a single cloud.
While few DBMS are truly cloud-native and can support multi-cloud in this way, it is possible to deploy almost any database across multiple clouds, although the person-hours required to set up and operate such a system can end up being cost-prohibitive, especially as it grows more complex.
Multi-cloud vs. hybrid cloud
Typically, the term multi-cloud refers to running on multiple public clouds (AWS, GCP, Azure, etc.). Hybrid cloud refers to running on a mix of at least one public and private cloud or on-premise system.
In the real world, however, these terms aren’t always used precisely, so you may hear hybrid-cloud systems referred to as multi-cloud, and vice-versa.
It’s also possible for a system to be both multi-cloud and hybrid cloud if it uses a combination of two or more public clouds together with a private cloud or on-prem system.
What are the benefits of a multi-cloud database?
The specific benefits of a multi-cloud database will depend on a company’s specific use case and the details of their deployment. In general, however, companies implementing multi-cloud databases are generally interested in one or more of these business goals:
1. Risk management
Limiting your database deployment to a single public cloud has risks, including but not limited to:
Outages: While public cloud region or whole-cloud outages are relatively rare, they happen. Most cloud providers either offer a single data center per region, or multiple data centers that are clustered in the same geographical area, meaning that the likelihood of a localized issue knocking out an entire cloud region is relatively high if you’re deployed on a single public cloud.
And when something like a regional outage does happen, it can be incredibly disruptive and costly – even an outage of just a few minutes is likely to cost large enterprises millions of dollars in lost business and reputational damage. Outages are also stressful for technical staff, and having to deal with them can harm work/life balance and, by extension, employee productivity and retention.
Even with multi-region deployments on a single cloud, the consequences of a regional outage can be significant, as latency for users in the affected region is likely to increase substantially, and the corresponding increase in traffic to other regions could overload your system, which now has fewer machines handling the same workload.
Vendor lock-in: Committing to a single public cloud means committing to their pricing and reliability – including any future changes in pricing and reliability – or facing a potentially costly and difficult migration later down the line.
Regulatory compliance: The laws that govern how companies handle customer data vary by region, and are changing fast. Maintaining the flexibility of a multi-cloud database deployment can help ensure companies remain in compliance and can more easily expand into new territories.
2. Cost
In some cases, multi-cloud database deployments can reduce costs, either directly (for example, via deals available from a particular cloud’s marketplace) or indirectly via the reduced hours required for database operations when companies opt for managed multi-cloud services.
3. Strategic planning
Many companies opt to implement multi-cloud databases as part of a broader push towards modernizing their tech stack and moving operations into the cloud to streamline development and operations.
Of course, these are just a few common reasons – many companies that have implemented multi-cloud databases have additional, company-specific reasons for doing so.
How to deploy a multi-cloud CockroachDB cluster
That’s enough about the why – how can you actually deploy a multi-cloud database?
The answer to that question depends on your DBMS of choice, but let’s walk through a quick demo of how easy it can be to deploy a single cluster of CockroachDB – a cloud-native, truly multi-cloud database – across three different cloud platforms.
Multi-cloud architecture tutorial
For the sake of this example, we’ll use the following data centers1:
- Digital Ocean, region nyc1
- Amazon Web Services, region us-east-1
- Google Compute Engine, zone us-east1
That gives us one data center in New York, one data center in Virginia, and one data center in South Carolina, respectively. Not bad for creating a cluster out of stock parts.
Note: This is not an endorsement of these particular cloud platforms. Choosing a cloud provider requires evaluating hardware performance, price, and geographic location for your particular workload.
Step 1: Launch the VMs
Get started by launching one VM in each of the three data centers listed above. Then launch an additional VM in one of the data centers, for a total of four VMs. Why the extra VM? Running a CockroachDB cluster with less than three nodes will trigger warnings about “underreplication,” and later we’ll be taking one of the four VMs offline to simulate a data center failure.
You might find the following guides helpful:
- How to Create Your First DigitalOcean Droplet
- Launching an Amazon EC2 Instance
- [Creating and Starting a [Google Compute Engine] VM Instance](<* https://cloud.google.com/compute/docs/instances/create-start-instance>)
CockroachDB works with any recent x64 Linux distribution. If you don’t have a preference, we recommend using the latest long-term support (LTS) release of Ubuntu. Be sure to configure networking to allow inbound and output TCP connections on both port 26257, for inter-node communication and SQL access, and port 8080, for the web admin UI.
We have more detailed walkthroughs in our deployment guides:
- Deploy CockroachDB on Digital Ocean
- Deploy CockroachDB on AWS EC2
- Deploy CockroachDB on Google Cloud Platform GCE
Step 2: Install and boot CockroachDB
Once you have VMs on each cloud provider up and running, it’s time to install and boot CockroachDB. You can follow our comprehensive installation instructions, or, as a quickstart, you can run the following commands on each VM, replacing PUBLIC-IP and DATA-CENTER appropriately:
$ wget -qO- https://binaries.cockroachdb.com/cockroach-v1.1.3.linux-amd64.tgz | sudo tar -xvz -C /usr/local/bin --strip=1
$ cockroach start --insecure --background \
--advertise-host PUBLIC-IP-SELF \
--join PUBLIC-IP-1,PUBLIC-IP-2,PUBLIC-IP-3,PUBLIC-IP-4 \
--locality data-center=DATA-CENTER
Remember: Real production deployments must never use –insecure! Attackers can freely read and write data on insecure cross-cloud deployments.
You can choose any value for DATA-CENTER, provided that nodes in the same data center use the same value. For example, you might launch two Digital Ocean nodes, each with --locality data-center=digital-ocean. CockroachDB uses this locality information to increase “replica diversity,” that is, preferring to store copies of data on machines in different localities rather than machines in the same locality.
From your local machine, initialize the cluster. You can use any of the nodes’ public IPs in this command.
$ cockroach init --host=PUBLIC-IP --insecure
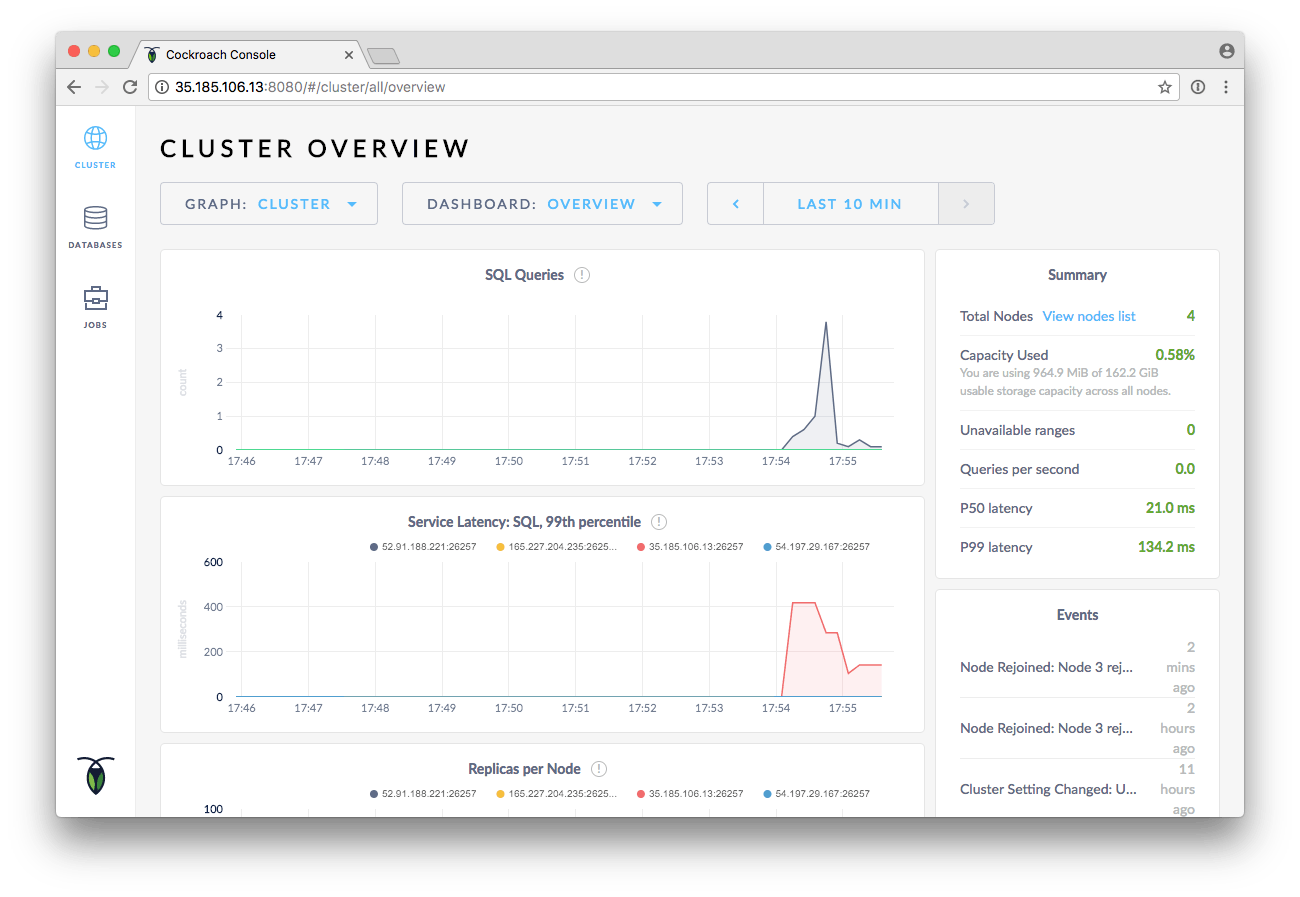
That’s it! You’ve created a cross-cloud CockroachDB cluster. If you take a peek at the admin UI, served at port 8080 on any of the nodes, you should see that four nodes are connected:
Step 3: Insert data
Now, let’s insert some data into the cluster. CockroachDB ships with some example data:
$ cockroach gen example-data | cockroach sql --host=PUBLIC-IP --insecure
Here’s a quick tour of this data:
$ cockroach sql --host=PUBLIC-IP --insecure
root@52.91.188.221:26257/> SHOW DATABASES;
+--------------------+
| Database |
+--------------------+
| crdb_internal |
| information_schema |
| pg_catalog |
| startrek |
| system |
+--------------------+
> SHOW TABLES FROM startrek;
+----------+
| Table |
+----------+
| episodes |
| quotes |
+----------+
> SELECT * FROM startrek.episodes ORDER BY random() LIMIT 5;
+----+--------+-----+----------------------+----------+
| id | season | num | title | stardate |
+----+--------+-----+----------------------+----------+
| 33 | 2 | 4 | Mirror, Mirror | NULL |
| 56 | 3 | 1 | Spock's Brain | 5431.4 |
| 35 | 2 | 6 | The Doomsday Machine | 4202.9 |
| 72 | 3 | 17 | That Which Survives | NULL |
| 55 | 2 | 26 | Assignment: Earth | NULL |
+----+--------+-----+----------------------+----------+
Looks like our CockroachDB cluster is a Star Trek whiz. We can verify that our episode table is safely stored on at least three nodes:
> SHOW TESTING_RANGES FROM TABLE startrek.episodes;
+-----------+---------+----------+--------------+
| Start Key | End Key | Replicas | Lease Holder |
+-----------+---------+----------+--------------+
| NULL | NULL | {1,2,3} | 1 |
+-----------+---------+----------+--------------+
(1 row)
Looks like our CockroachDB cluster is a Star Trek whiz. We can verify that our episode table is safely stored on at least three nodes:
> SHOW TESTING_RANGES FROM TABLE startrek.episodes;
+-----------+---------+----------+--------------+
| Start Key | End Key | Replicas | Lease Holder |
+-----------+---------+----------+--------------+
| NULL | NULL | {1,2,3} | 1 |
+-----------+---------+----------+--------------+
(1 row)
CockroachDB automatically splits data within a table into “ranges,” which are then copied to three “replicas” for redundancy in case of node failure. In this case, the entire table fits into one range, as indicated by the Start Key and End Key columns. The Replicas column indicates this range is replicated onto node 1, node 2, and node 32.
Note: If your Replicas column only lists one node, your nodes likely can’t communicate over the network. Remember, port 26257 needs to allow both inbound and outbound connections. Consult our Cluster Setup Troubleshooting guide, or ask for help in our Gitter channel or on our forum.
In the cluster shown here, nodes 1 and 4 are in the same data center. Since the table is stored on nodes 1, 2, and 3, that means we have one copy of the table in each of the data centers, just as we’d hoped! Fair warning: node numbers are not assigned deterministically and will likely differ in your cluster.
Step 4: Simulate data center failure
Now, let’s simulate a full data center failure. Power off the VM in one of the data centers with only one VM. In this example, we’ll power off node 3. Make sure your SQL session is connected to a node besides the node you’re taking offline. (In a real deployment, to avoid this point of failure, you’d use a load balancer to automatically reroute traffic to a live node.) First, notice that even in the moment after node 3 goes offline, querying the episodes table still succeeds!
> SELECT * FROM startrek.episodes ORDER BY random() LIMIT 5;
+----+--------+-----+-----------------------------+----------+
| id | season | num | title | stardate |
+----+--------+-----+-----------------------------+----------+
| 27 | 1 | 27 | The Alternative Factor | 3087.6 |
| 59 | 3 | 4 | And the Children Shall Lead | 5029.5 |
| 18 | 1 | 18 | Arena | 3045.6 |
| 13 | 1 | 13 | The Conscience of the King | 2817.6 |
| 21 | 1 | 21 | The Return of the Archons | 3156.2 |
+----+--------+-----+-----------------------------+----------+
When a node dies, CockroachDB immediately and automatically reroutes traffic to one of the remaining replicas. After five minutes, by default, the cluster will mark a down node as permanently “dead” and move all of its replicas to other nodes. In this example, node 3 is no longer in the replica set:
> SHOW TESTING_RANGES FROM TABLE startrek.episodes;
+-----------+---------+----------+--------------+
| Start Key | End Key | Replicas | Lease Holder |
+-----------+---------+----------+--------------+
| NULL | NULL | {1,2,4} | 2 |
+-----------+---------+----------+--------------+
Note that the replica set now includes two nodes in the same data center, node 1 and node 4. With only two data centers, CockroachDB will reluctantly put two copies of the data in the same data center, as a total of three copies is better than only two copies. If the third data center does come back online, or if another data center is connected to the cluster, CockroachDB will again balance replicas across data centers.
Conclusion
That’s all there is to it! With very little configuration, we have a multi-cloud deployment of CockroachDB that checks all the boxes: nodes in three data centers along the east coast to minimize latency without compromising availability, even in the face of total data center failure.
If you’re not yet ready to commit to a permanent multi-cloud deployment, CockroachDB’s multi-cloud support can still be instrumental in providing operational flexibility. Check out how CockroachDB unlocks zero-downtime migrations from one cloud to another.
And if you’re in the mood to be entertained, watch CockroachDB get deployed across 15 different clouds simultaineously:
Illustration by Zoë van Dijk
-
Most cloud providers charge an egress bandwidth fee for network traffic that leaves the data center. Be sure to factor this additional cost into account before launching a multi-cloud cluster.\ ↩︎
-
Technically, the Replicas column lists store IDs, not node IDs. In the default configuration we’ve described in this tutorial, however, every node has exactly one store, so store IDs correspond one-to-one to node IDs. ↩︎


