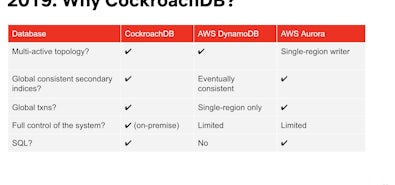

Databases are the beating heart of every business in the world, running the gamut from humble spreadsheets to thousands of servers linked into vast supercomputers. And they’ve been evolving rapidly. Most of us at Cockroach Labs have spent our careers watching them progress, often actively struggling to overcome their limitations when the task at hand outstripped their capabilities.
But first, why “Cockroach”? If you can get past their grotesque outer aspect, you’ve got to give them credit for sheer resilience. You’ve heard the theory that cockroaches will be the only survivors post-apocalypse? Turns out modern database systems have a lot to gain by emulating one of nature’s oldest and most successful designs. Survive, replicate, proliferate. That’s been the cockroach model for geological ages, and it’s ours too. It doesn’t hurt that the name itself is resilient to being forgotten.
In the early 2000s when we were working at Google, it wasn’t long before we ran smack into a database headache all too common in the industry: application-level sharding. What happens when you have too much data to store in a database? Easy, you split it up and put some into one database, some into another, and so on, creating as many shards (i.e. partitions) as necessary. But what happens when the data growth doesn’t stop? The challenge was, succinctly: more shards, more problems, which created customer downtime, overloaded servers, and mounting complexity. We developed a healthy appreciation for the difficulties of scale.
Fast forward to the mid-2000s, when Google ushered in the NoSQL movement. NoSQL sacrificed some capabilities of traditional RDBMS systems for simplicity. A simpler design allowed transparent scalability on commodity hardware. Now applications could be developed as though against a single database, but one capable of reaching formerly unheard-of sizes. We then watched as those simplifications became an Achilles' heel for developers, leading to increasingly complex application logic to workaround missing functionality, like transactions. These pain points in turn required new designs to restore consistency and transactionality, as next-generation systems replaced the old.
In 2012 we left Google to create a private photo sharing platform called Viewfinder. In this day and age, dreams of providing a service for billions of users are not misplaced fantasies, and our dreams were big. But they collided with reality as we struggled to find open source replacements for the excellent infrastructure we’d left behind. We muddled through, built decent, sometimes complex workarounds where possible, used duct tape where necessary. Turns out there’s simply never enough time to solve this problem when it’s not your primary goal.
So we decided to make it our priority. We started Cockroach Labs with a clear objective: build the database we’d been itching after for years, and build it as open source, from the start. The mission is simple, but as big and as broad as any we could happily commit to: Make Data Easy. The database we want scales, survives disasters, is always consistent, and supports abstractions that make it easy to use. We’d rather spend time quickly building and iterating products, not engineering solutions to database shortcomings. This is the database we want when we start our next company. And the one after that.
Today, we’re launching CockroachDB for everyone. Use it. Build on it. Contribute to it!
Ben, Peter & Spencer